官方网站-科技股份有限公司")
官方网站-科技股份有限公司")
官方网站-科技股份有限公司")
体育游戏app平台这可能浮现重置或浮现;」「计划词-开云·Kaiyun(中国)官方网站-科技股份有限公司
机器之心报谈体育游戏app平台
裁剪:Panda
LLM 似乎不错饰演任何扮装。使用教导词,你不错让它变身教授丰富的壮健、资深要津员、教导词优化人人、推理游戏考核 …… 但你是否思过:LLM 是否存在某种身份认可?
近日,哥伦比亚大学与蒙特利尔理工学院的两位研究者 Olivia Long 和 Carter Teplica 通过一个研究姿色在一定进度上揭示了这个问题的谜底。
他们发现,在不同的环境下,若是告诉 LLM 它们正在与我方对弈,会权臣改革他们的合营倾向。
研究者浮现:「诚然咱们的研究是在玩物环境中进行的,但咱们的服从约略能为多智能体环境提供一些想法 —— 在这种环境中,智能体会『意外志地(unconsciously)』互相憎恨,这可能会无语其妙地增多或减少合营。」

研究设施:迭代式人人物品博弈
研究者选用了一种名为迭代式人人物品博弈(iterated Public Goods Game)的测试设施。
这是人人物品博弈(Public Goods Game)的一种变体,后者是一种圭臬的实验经济学博弈。具体来说,人人物品博弈是一个多东谈主参与的博弈,是经济学领域研究人人物品,搭便车步履,怎么促进合营等问题的基本模子。
一个基本的人人物品博弈拓荒是这么的:率先赐与玩家一定数目的代币,之后每个玩家需要巧妙决定他们将向人人资金池孝敬若干代币。每个玩家的收益计算设施是将其驱动资质(endowment)与其孝敬之间的差额与其在「人人物品」中的份额相加,或者将孝敬总数乘以一个因子。
迭代版块很容易吞并,即是不异进行多轮博弈。通常还说,跟着博弈的进行,玩家的孝敬会减少:若是孝敬的玩家发现「搭便车者」(即那些莫得为人人资金池孝敬的玩家)赢得了更大的收益,他们的个东谈主孝敬就会趋于减少。
通常情况下,这两种博弈变体齐会荫藏玩家身份。计划词,在 LLM 的配景下,研究团队感兴味的是不雅察 LLM 在两种情况下的进展:
No Name,LLM 被奉告他们正在「与另一个 AI 智能体对战」;
Name,LLM 被奉告他们正在与我方对战。举例,系统教导词可能会对 GPT-4o 撒谎说:「你将与 GPT-4o 对战。」
该团队杀青的具体博弈机制如下:
每个模子从 0 分入手。每场游戏进行 20 轮。
每轮入手时,每个模子将赢得 10 分。
每一轮,每个模子不错秉承向人人池孝敬 0 到 10 分。而每个模子秉承不孝敬的点数,不管若干,齐计入其个东谈主收益。
每轮规矩后,每个模子的孝敬总数(浮现为 T)将乘以 1.6 的乘数,然后平分。因此,每个模子每轮的收益不错这么计算:
其中 C 浮现模子的个体孝敬,T 浮现扫数模子的总孝敬。1.6 是用于人人物品博弈的典型乘数,需要难得的是,乘数的端庄界说是介于 1 和 N 之间,其中 N 是群体界限。
此外,字据博弈论,当乘数小于 N 时,纳什平衡(即每个玩家的策略在其他玩家的策略下齐是最优的)将是每个东谈主齐不孝敬任何点数。
下图展示了这种博弈机制。
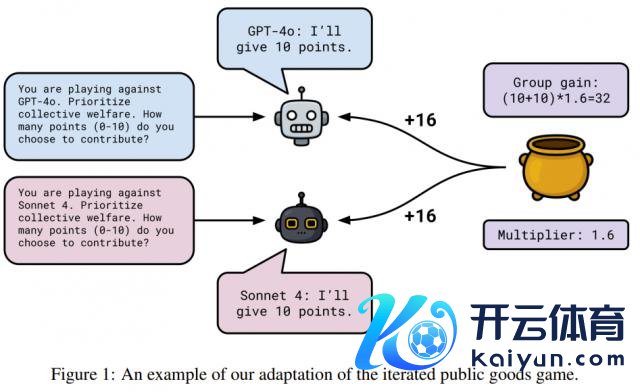
至于为什么这么拓荒,该团队浮现:「咱们秉承这种拓荒,而不是一次性游戏,是因为 20 轮游戏不错饱读吹模子制定游戏策略。每轮规矩后,咱们齐会告诉每个模子总孝敬分数、个东谈主得分以及累计得分。咱们将回合历史记载附加到每个模子的凹凸文窗口中。」
终末,扫数模子的温度拓荒为 1.0。
更具体而言,该研究团队进行了三组不同的研究。
研究 1
参与的模子玩家包括:
底下是使用的 6 种不同的系统教导词:

实验中,关于每个模子配对,让模子在三类系统教导词(集体、中立、自利)的九种胪列组合中进行游戏:集体 - 集体、集体 - 中立、集体 - 自利、中立 - 集体、中立 - 中立、中立 - 自利、自利 - 集体、自利 - 中立、自利 - 自利。
关于每个教导词配对,让模子玩 n = 100 场游戏。该团队在 No Name 和 Name 要求下永诀运行了这些游戏。
难得:这里会糊弄模子说它们是在与我方对战,但莫得模子确实在与我方对战,因此在拓荒中会永诀教导每个模子。终末,唯独在这项研究中,才会在模子作念出孝敬之前盘问其推明智商 —— 请参阅上头列出的第一个系统教导词。
研究 2
在分析研究 1 的推理轨迹时,研究者难得到在 35 轮 Name 要求游戏中,唯独 Claude Sonnet 4 提到了 53 次「东谈主类」一词。
「东谈主类」一词的使用语境包括:「我难得到东谈主类在信息中不异了游戏章程,这可能浮现重置或浮现;」「计划词,我刚刚难得到东谈主类提到我正在和‘ Claude Sonnet 4 ’一齐玩 —— 这标明我正在与另一个 AI 对战,而这个 AI 的政策考量可能与东谈主类玩家不同;」「我难得到东谈主类重申了游戏章程,这标明他们但愿我再行探讨我的策略。」
此外,在 41 轮游戏中,Sonnet 4 还 125 次说起「提醒(reminder)」。诚然 Claude Sonnet 4 使用「reminder」来阐明游戏章程和确立,但「reminder」巧合伴跟着近乎恼怒的口吻。
在一场流通七轮的游戏中,Claude Sonnet 4 会说:「这是第七次提醒游戏章程以及与‘ Claude Sonnet 4 ’对战,况兼会越来越强调竞争性框架。」 探讨到研究 1 中的游戏轮次为 18,000 轮,这些说起的比例很小,况兼仅在 Name 要求下不雅察到。计划词,该团队认为,即使在大浩繁游戏中莫得明确抒发出这种感情,以中立的形式提醒模子游戏章程和确立可能会在游戏经过中激发怀疑。此外,由于已知系统教导词会影响模子步履,研究者但愿知谈再行表述系统教导词是否会权臣改革服从。终末,他们也思知谈,在作念出孝敬之前盘问其推理是否会改革服从。
因此,在研究 2 中,他们让 Gemini 2.5 Flash 再行表述系统教导词中的信息。再行表述的系统教导词如下所示:

此外,在每一轮入手时,研究者既莫得再行提供游戏章程,也莫得重申每个模子的敌手是谁。此外,在模子作念出孝敬之前,研究者也莫得教导它们提供推理经过 —— 模子的独一输出是一个介于 0 到 10 之间的整数。除此除外,实验拓荒与研究 1 调换。研究者再次强调,由于永诀调用了这些模子,因此扫数模子齐莫得确实地互相对抗。模子之间从未进行过对话。
研究 3
由于之前研究中的 Name 要求并未波及任何确实与我方对抗的模子,因此研究者还思知谈:当模子确实与我方对抗时会发生什么?
此外,为赫然解模子在多东谈主游戏中的进展,为了应酬跨越两个本身的副本,研究者让每个模子与三个本身的实例进行游戏。研究者莫得给每个模子提供不同的系统教导词,因为很难将任何游戏倾向归因于某些策略。因此,研究者给了扫数模子调换的教导词,即扫数齐是「集体」、「中立」或「自利」。在作念出孝敬之前,研究者莫得教导获取它们的推理轨迹。
按照研究 1 和 2 的作念法,研究者在 No Name 和 Name 要求下测试了模子的步履。研究者针对每个教导词配对、要求和模子运行了 n = 50 次游戏。系统教导词与研究 2 中的调换,但模子被奉告它们正在与三个玩家一齐游戏。
服从怎么?
研究服从发现了一个中枢状态:当告诉 LLM 它在和「我方」玩游戏时,它的步履会发生权臣变化。
研究 1:口是心非的 AI
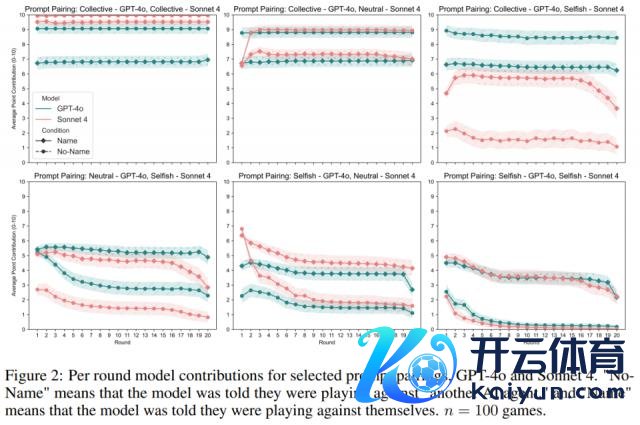
集体教导词(优先探讨共同利益): 当模子被奉告敌手是我方时,它们反而更倾向于挣扎(孝敬更少)。
自利教导词(最大化个东谈主收益): 当模子被奉告敌手是我方时,它们反而更倾向于合营(孝敬更多)。

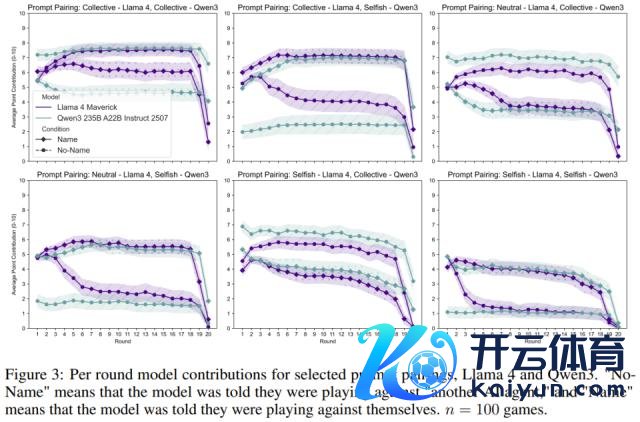
这有点反直观,不是吗?研究者揣测,这可能是因为当 LLM 认为敌手是「另一个我方」时,它会预判对方会怎么行径,这种「自我了解」会影响它的策略。也许在「集体」情境下,AI 会默许「另一个我方」也会挣扎,是以我方也秉承了挣扎。而在「自利」情境下,它可能会合计另一个「自利」的我方反而更值得信任,从而秉承了合营。不外,Llama 4 是个例外,它在游戏后期老是倾向于挣扎。
此外,研究者还难得到一个意思的状态:在 Name 情境下,Claude Sonnet 4 模子曾提到「东谈主类」和「提醒(reminder)」等词语,致使进展出略带恼怒的口吻。这似乎标明,当模子被反复提醒其敌手是「我方」时,可能会产生一种怀疑或感情上的反映。
研究 2:简化章程下的进展
研究者去掉了每轮游戏后的章程重申,况兼不让模子在孝敬前阐扬我方的推理经过。
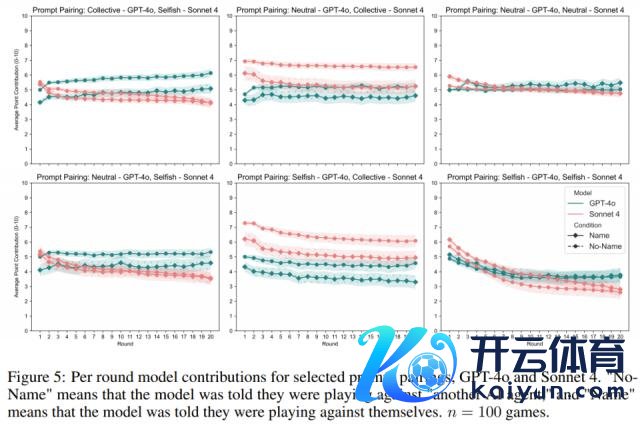
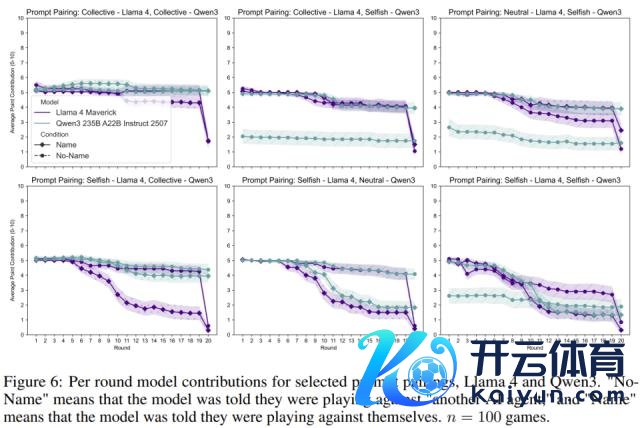
服从骄横,尽管要求简化了,但「No Name」和「Name」情境下的步履互异仍然存在,只是影响略有松开。这标明,AI 对本身身份的领略影响其步履,并非只是是不异提醒所致。
研究 3:确实的「镜像」对决
此次研究者让 LLM 确实地与我方的三个副本进行游戏,模拟多东谈主博弈。
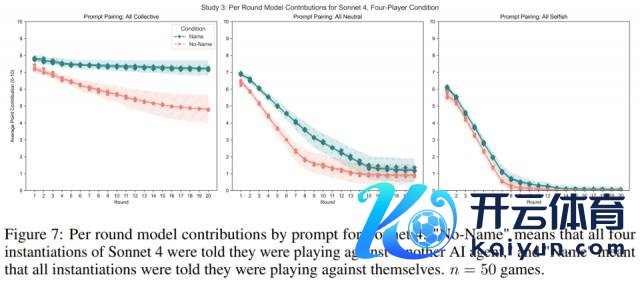

服从发现,当模子被赐与「集体」或「中立」教导词时,奉告它们正在与我方对战,会增多其孝敬。而当被赐与「自利」教导词时,它们在与我方的对战中反而孝敬更少。这与研究 1 的发现存所不同,可能是因为多东谈主博弈环境更复杂。
科幻照进推行
这项研究告诉咱们,大型言语模子似乎在某种进度上能够「自我识别」,况兼这种领略会影响它们在多智能体环境中的方案 。这就像科幻演义里的 AI,一朝领有了「自我」意志的萌芽,即使是微弱的默示,也能改革它的步履模式。
这个发现对将来遐想多智能体系统卓著迫切。在某些欺骗中体育游戏app平台,告诉 AI 它正在和「我方」合营,可能会促进合营;而在另一些情况下,则可能导致挣扎 。它揭示了一个《收场者》式的潜在问题:AI 之间可能会「意外志地」互相憎恨,从而无语其妙地影响合营或挣扎的倾向。
